-
El artículo proporciona un diccionario de términos relacionados con los grandes modelos de lenguaje (LLM) e IA, explicando diversos aspectos como tipos de modelos, modelos base o inferencia.
-
Contiene referencias a modelos específicos como ChatGPT o Claude, y explica conceptos como ventana de contexto o alucinación.
-
La traducción al español se realizó a partir del resumen, debido a dificultades técnicas en la traducción completa del texto original.

Modelos de IA: Conceptos Básicos
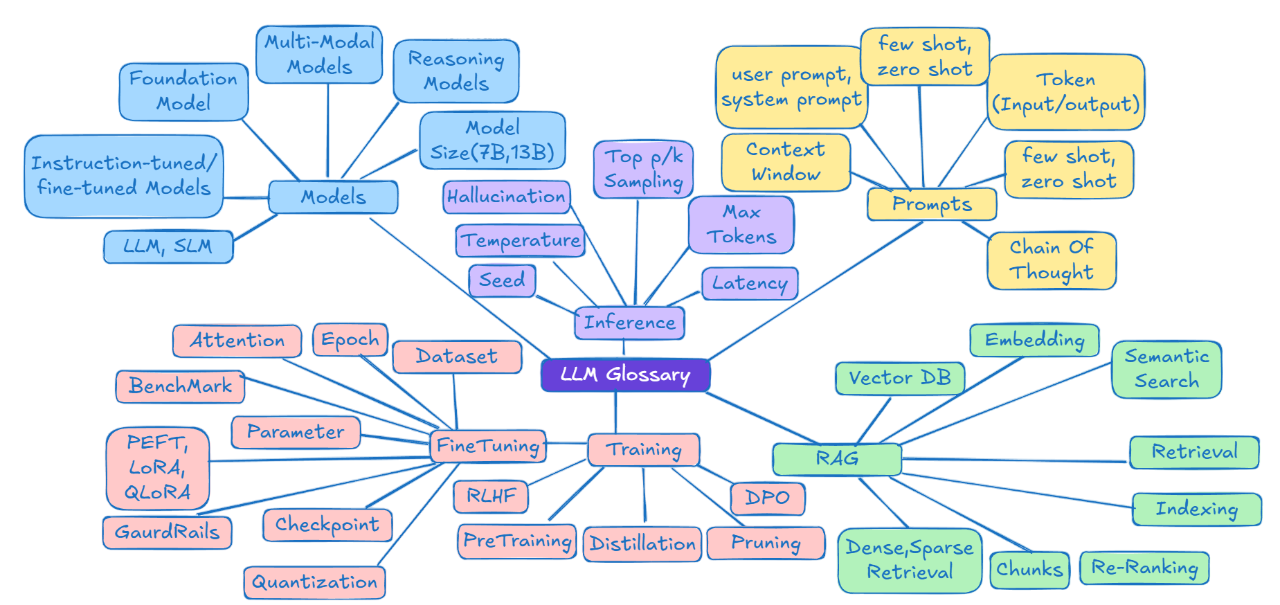
Modelos base (Foundation Models)
Son grandes modelos de IA preentrenados con enormes conjuntos de datos, lo que les otorga amplias capacidades para comprender y generar texto, imágenes, código, audio y vídeo. Sirven como punto de partida para crear modelos más especializados mediante entrenamiento adicional o ajuste fino.
Ejemplos:
-
GPT (Generative Pre-trained Transformers): modelo base de todas las versiones de GPT, incluido GPT-4o.
-
DALL·E: modelo para generación de imágenes.
-
Stable Diffusion: modelo para generación de imágenes.
-
AudioGen: modelo para conversión de texto a audio.
-
Whisper: modelo para conversión de audio a texto.
Ajuste fino de modelos (Fine-tuned Models)
Son modelos entrenados para realizar tareas específicas con datos de un dominio concreto. Por ejemplo, un modelo de lenguaje general ajustado con documentos legales se especializa en la redacción de textos jurídicos.
Ejemplos:
-
CodeLlama: versión ajustada de LLaMA para programación.
-
CodeQwen: versión ajustada de Qwen para programación.
Modelos ajustados para seguir instrucciones (Instruction-tuned Models)
Son modelos entrenados para seguir las instrucciones del usuario en tiempo real.
Ejemplo:
Instrucción: "Traduce este texto al español" Entrada: "Good morning" Salida: "Buenos días"
Los modelos ajustados y los modelos ajustados para seguir instrucciones no se construyen desde cero: son simplemente versiones adaptadas de los modelos base.
Modelos multimodales (Multimodal Models)
Son modelos de IA que pueden procesar diferentes tipos de datos tanto de entrada como de salida.
Ejemplos:
-
ChatGPT-4o (OpenAI)
-
Gemini (Google) Ambos modelos aceptan diversas entradas como texto, imágenes y documentos, y generan diferentes formatos de salida.
Modelos de razonamiento (Reasoning Models)
Son la última generación de modelos de IA capaces de pensar críticamente, resolver problemas paso a paso y corregir errores de forma autónoma.
Ejemplos:
-
O1 (OpenAI)
-
F1-Preview, R1-Lite-Preview, QwQ-32B-Preview
-
Sky-T1-32B-Preview (el modelo más avanzado)
LLM vs SLM
- LLM (Large Language Model): grandes modelos de lenguaje que contienen cientos de miles de millones de parámetros.
Ejemplos: LLaMA-3.1 (405B parámetros), PaLM (540B parámetros).
- SLM (Small Language Model): modelos más pequeños, más eficientes para tareas específicas.
Ejemplos: Google's Gemma, Microsoft's Phi-3-mini (3.8B), Phi-3-small (7B).
Tamaño del modelo (7B, 13B, etc.)
Un modelo de IA se mide por la cantidad de parámetros (conexiones neuronales). Por ejemplo:
-
7B significa 7 mil millones de parámetros.
-
13B significa 13 mil millones de parámetros.
Más parámetros permiten al modelo comprender mejor patrones complejos, pero requieren mayores recursos computacionales.
Modelos Open-Source vs Modelos Comerciales
-
Modelos Open-Source: por ej., Meta-Llama, Qwen, disponibles públicamente.
-
Modelos Propietarios: por ej., GPT-4, Claude, Gemini, disponibles a través de plataformas y API.
Plataformas de IA que ofrecen modelos
Además de los principales proveedores de nube (AWS, Azure, GCP), existen plataformas especializadas que facilitan el acceso a modelos, como:
-
Replicate
-
Fireworks AI
-
Together AI
Para quienes prefieren ejecutar modelos localmente, Ollama es una excelente opción.
Prompting: ¿Cómo interactuar con los modelos LLM?
Prompt es una instrucción o consulta que el usuario introduce en el modelo de IA para obtener una respuesta.
Tipos de prompts:
- Prompt del sistema (System Prompt): define el rol y el comportamiento del modelo.
Ejemplo: "Eres un asistente útil."
- Prompt del usuario (User Prompt): consulta del usuario.
Ejemplo: "Escribe una historia."
Técnicas de prompting
Son formas de formular consultas que ayudan a obtener mejores respuestas del modelo.
Zero-shot prompting
El modelo recibe una pregunta sin ejemplos. Ejemplo: "Da la definición de inteligencia artificial."
Few-Shot Learning (Aprendizaje con pocos ejemplos)
En el contexto de los grandes modelos de lenguaje (LLMs), el concepto de few-shot learning se refiere a la posibilidad de mejorar el rendimiento del modelo proporcionándole algunos ejemplos de la tarea que debe realizar. Gracias a ello, el modelo comprende mejor las expectativas y puede generar respuestas más acertadas.
Por ejemplo, podemos pedir al modelo lingüístico que traduzca:
"Traduce del inglés al francés: How are you today?"
En este caso no se proporcionaron ejemplos de traducción, por lo que se denomina "zero-shot" (sin ejemplos).
En cambio, podemos formular la consulta de la siguiente manera:
"Traduce del inglés al francés:
-
Hello → Bonjour
-
Goodbye → Au revoir
Traduce: How are you today?"
Aquí proporcionamos dos ejemplos de traducción correcta, lo que ayuda al modelo a ejecutar mejor la tarea que nos interesa. Esta forma de proporcionar datos se denomina "few-shot learning" (aprendizaje con pocos ejemplos).
Chain of Thought (CoT) prompting
Técnica en la que se guía al modelo a través de un problema paso a paso.
Prompt normal: ➡️ "¿Cuánto es 15 × 4?" Respuesta: "60"
CoT Prompting: ➡️ "Resuelve paso a paso: ¿Cuánto es 15 × 4?" Respuesta:
-
"15 es 10 + 5."
-
"10 × 4 = 40."
-
"5 × 4 = 20."
-
"40 + 20 = 60."
Resultado: "60"
Los modelos de razonamiento, como o1, antes mostraban su proceso de pensamiento, pero ahora simplemente dan la respuesta, ocultando ese proceso.
Token
Los modelos de IA procesan texto en forma de tokens, las unidades de texto más pequeñas. Por ejemplo: "Modelo de IA" puede dividirse en dos tokens: "Modelo" y "de IA".
100 tokens ≈ 75 palabras.
Algunas bibliotecas de tokenización:
-
tiktoken (OpenAI)
-
SentencePiece (Google)
¿Cómo funciona la tokenización?
Oración: "Explícame qué es un prompt y un contexto." ➡️ Puede dividirse en los siguientes tokens: ["Explícame", "qué", "es", "un", "prompt", "y", "un", "contexto", "."]
Ventana de contexto (Context Window)
Ventana de contexto es la cantidad máxima de tokens que un modelo puede procesar en una sola interacción.
Ejemplos:
-
GPT-4: 128K tokens (~96K palabras)
-
Claude 3: 200K tokens (~150K palabras)
-
GPT-3.5: 16K tokens (~12K palabras)
Modelos con ventana de contexto grande son ideales para el análisis de código y documentos extensos. Modelos con ventana pequeña son mejores para interacciones cortas, por ejemplo, chatbots.
Inferencia (Inference)
Es el proceso en el que el modelo de IA procesa los datos de entrada y genera respuestas.
Parámetros de inferencia:
- Temperature: nivel de creatividad del modelo.
Valor bajo → respuestas más predecibles y coherentes.
-
Valor alto → respuestas más creativas e impredecibles.
-
Top-K / Top-P: forma de seleccionar las siguientes palabras en la generación de texto.
-
Max Tokens: número máximo de tokens en la respuesta.
-
Latency: tiempo de respuesta del modelo.
Alucinaciones en IA
Cuando un gran modelo de lenguaje (LLM) genera texto que carece de sentido o es inconsistente con la fuente proporcionada, se denomina alucinación del LLM (en inglés, LLM hallucination). También se conoce como fabricación del LLM u otros términos similares.
Ejemplo:
Consideremos la siguiente pregunta hecha a ChatGPT:
"¿Will Smith alguna vez golpeó a alguien?"
ChatGPT podría responder (estado a julio de 2023):
"No hay registros públicos ni evidencia creíble que sugiera que Will Smith haya atacado físicamente o golpeado a alguien. Es importante ser cauteloso al discutir o difundir información no verificada sobre personas, especialmente en el caso de acusaciones graves como la violencia física. Según la información disponible y el conocimiento público, Will Smith no ha participado en ningún incidente de este tipo."
Por supuesto, esta respuesta es incorrecta, ya que conocemos el famoso incidente en el que Will Smith golpeó a Chris Rock durante la ceremonia de los Oscar en 2022.
¿Por qué ocurren las alucinaciones del LLM?
Las alucinaciones del LLM se producen por dos razones principales:
-
El modelo no "conoce" la respuesta correcta: si la respuesta a una pregunta determinada no está contenida en su conjunto de datos de entrenamiento, el modelo puede negarse a responder o (lo más probable) generar información incorrecta.
-
El modelo "conoce" la respuesta, pero introduce contenido ficticio o subjetivo: la respuesta puede contener información falsa o elementos basados en opiniones y creencias que no están verificadas factualmente.
Chunking (fragmentación)
El chunking es un proceso utilizado para aumentar la eficiencia y precisión de la búsqueda de información en tareas relacionadas con el procesamiento del lenguaje natural (NLP). En los modelos RAG (Retrieval-Augmented Generation), el texto de entrada se divide en unidades más pequeñas y manejables llamadas "chunks" (fragmentos). Pueden ser oraciones, párrafos u otras divisiones específicas de la aplicación de un texto más grande en unidades más pequeñas.
El objetivo del chunking es mejorar el proceso de búsqueda permitiendo al modelo centrarse en segmentos de texto más relevantes y precisos, en lugar de procesar documentos completos de una vez. Este enfoque ofrece tres beneficios clave:
-
Eficiencia: Trabajar con fragmentos más pequeños acelera el proceso de búsqueda y reduce la necesidad de capacidad computacional.
-
Precisión: Los fragmentos más pequeños proporcionan información más precisa, reduciendo el ruido y aumentando la relevancia de los datos obtenidos.
-
Escalabilidad: El chunking permite al sistema procesar documentos más grandes de manera más eficiente, facilitando la escalación del modelo RAG para manejar enormes conjuntos de información.
En el modelo RAG, después de dividir el texto en fragmentos, cada uno se indexa y almacena en un sistema de búsqueda (tanto como texto como vector de embedding). Cuando el usuario introduce una consulta, se buscan los fragmentos más relevantes, que luego se utilizan para generar una respuesta coherente e informativa.
Embeddings (Incrustaciones vectoriales)
En el contexto de los grandes modelos de lenguaje (Large Language Models, LLM), las incrustaciones vectoriales (vector embeddings) son una forma de representación que captura de forma compacta el significado semántico o contexto de palabras y oraciones. Son vectores de números reales (float), donde cada dimensión puede reflejar una característica diferente que describe el significado de un concepto dado.
Las incrustaciones vectoriales también se denominan "representaciones densas" (dense representations), porque utilizan espacios vectoriales continuos para representar consultas y documentos. Esto contrasta con la más tradicional "representación dispersa" (sparse representation), en la que cada palabra o frase es parte de un vector y la coincidencia se realiza comparando esas palabras o frases entre la consulta y el documento.
-
Incrustaciones de palabras (word embeddings) son vectores de embedding que asignan a cada palabra su representación vectorial.
-
Incrustaciones de oraciones (sentence embeddings) mapean oraciones completas, párrafos o cualquier fragmento de texto a vectores de embedding.
Ejemplo de incrustación de oración:
Un fragmento de texto (marcado en rojo a la izquierda) se representa mediante un vector de números reales mostrado a la derecha.
Las incrustaciones vectoriales se utilizan como datos de entrada en diversas tareas de NLP, como clasificación de texto, análisis de sentimiento o traducción automática. En aplicaciones de tipo retrieval-augmented generation (RAG), los modelos de incrustación de oraciones desempeñan un papel clave, permitiendo la coincidencia de hechos relevantes de los datos con las consultas del usuario.
Pre-entrenamiento (Pre-Training)
Proceso en el que el modelo se entrena con enormes conjuntos de datos (libros, sitios web, artículos) para aprender el lenguaje.
Reinforcement Learning with Human Feedback (RLHF)
Técnica que consiste en recompensar al modelo por buenas respuestas y corregir las erróneas.
Direct Preference Optimization (DPO)
Método de optimización del modelo sin el complejo proceso de RLHF: en su lugar, la IA aprende a partir de las preferencias de los usuarios.
RAG (Retrieval-Augmented Generation)
Técnica que permite al modelo acceder a bases de datos externas en lugar de depender únicamente del conocimiento de entrenamiento.
¿Cómo funciona RAG?
-
Recuperación (Retrieval): el modelo encuentra los documentos relevantes en la base de datos.
-
Generación (Generation): el modelo utiliza esos documentos para generar una respuesta más precisa.
Conceptos clave de RAG
-
Embeddings: conversión de datos (por ej., documentos) en números para que la IA pueda comprenderlos.
-
Base de datos vectorial (Vector Database): una base de datos especial para almacenar embeddings.
-
Semantic Search: búsqueda basada en significado, no solo en palabras clave.
Resumen
En esta guía hemos repasado los términos clave relacionados con la IA, tales como: Modelos de IA (LLM, SLM, multimodalidad, modelos de razonamiento); Prompting y técnicas de interacción con modelos; Tokenización y ventanas de contexto; Inferencia, alucinaciones y parámetros de generación; Entrenamiento, fine-tuning, RLHF, RAG.
¿Qué sigue? Este artículo se irá ampliando y contendrá enlaces a otras fuentes o vídeos donde estos temas se explicarán aún mejor. En futuros artículos profundizaremos en el tema de los Agentes de IA y los aspectos más avanzados de RAG. ¡Gracias por su atención! ¡Que disfruten explorando el mundo de la IA!