-
Cet article fournit un glossaire des termes liés aux grands modèles de langage (LLM) et à l'IA, expliquant différents aspects tels que les types de modèles, les modèles de base ou l'inférence.
-
Il contient des références à des modèles spécifiques comme ChatGPT ou Claude, et explique des concepts tels que la fenêtre de contexte ou l'hallucination.
-
La traduction a été réalisée à partir d'un résumé, en raison de difficultés techniques pour traduire intégralement le texte original.

Modèles d'IA : concepts fondamentaux
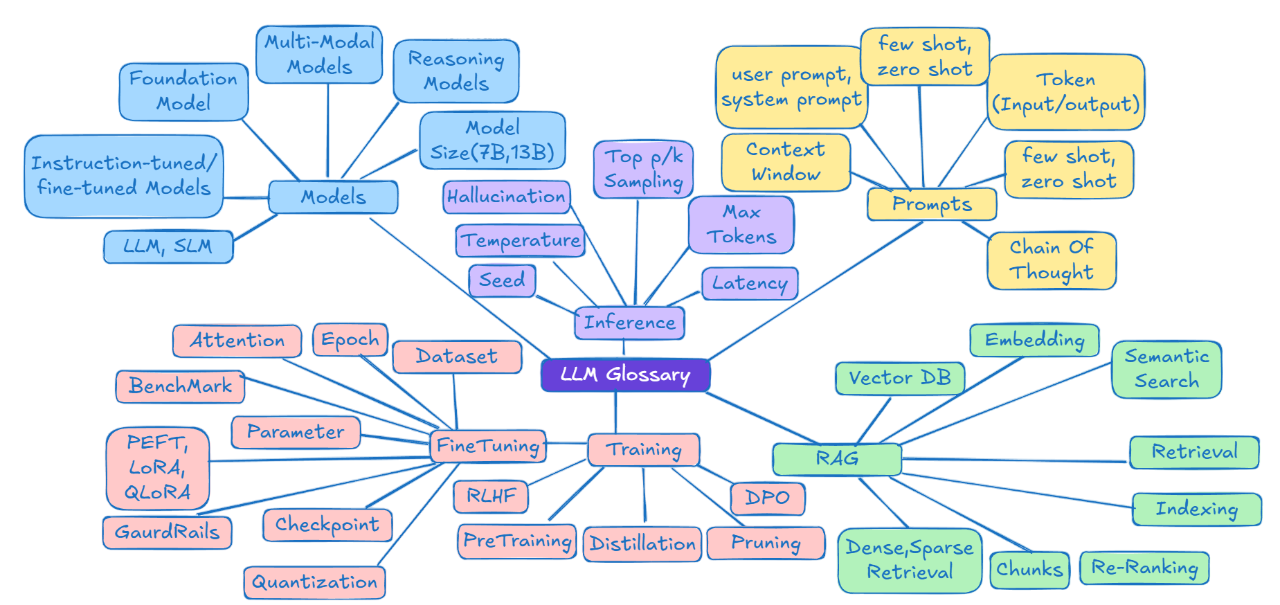
Modèles de base (Foundation Models)
Ce sont de grands modèles d'IA pré-entraînés sur d'immenses ensembles de données, ce qui leur confère de larges capacités de compréhension et de génération de texte, d'images, de code, de son et de vidéo. Ils servent de point de départ pour créer des modèles plus spécialisés par le biais d'un entraînement ou d'un ajustement complémentaire.
Exemples :
-
GPT (Generative Pre-trained Transformers) — modèle de base de toutes les versions de GPT, y compris GPT-4o.
-
DALL·E — modèle de génération d'images.
-
Stable Diffusion — modèle de génération d'images.
-
AudioGen — modèle de conversion texte-audio.
-
Whisper — modèle de conversion audio-texte.
Ajustement fin des modèles (Fine-tuned Models)
Ce sont des modèles entraînés pour effectuer des tâches spécifiques sur des données d'un domaine particulier. Par exemple, un modèle de langage général ajusté sur des documents juridiques devient spécialisé dans la rédaction de textes juridiques.
Exemples :
-
CodeLlama — version ajustée de LLaMA pour la programmation.
-
CodeQwen — version ajustée de Qwen pour la programmation.
Modèles ajustés pour suivre des instructions (Instruction-tuned Models)
Ce sont des modèles entraînés pour suivre en temps réel les instructions de l'utilisateur.
Exemple :
Instruction : « Traduisez ce texte en espagnol » Entrée : « Good morning » Sortie : « Buenos días »
Les modèles ajustés et les modèles ajustés pour suivre des instructions ne sont pas construits à partir de zéro — ce sont simplement des versions adaptées des modèles de base.
Modèles multimodaux (Multimodal Models)
Ce sont des modèles d'IA capables de traiter différents types de données en entrée et en sortie.
Exemples :
-
ChatGPT-4o (OpenAI)
-
Gemini (Google) Ces deux modèles acceptent différentes entrées, telles que le texte, les images et les documents, et génèrent différents formats de sortie.
Modèles de raisonnement (Reasoning Models)
C'est la dernière génération de modèles d'IA, capables de penser de manière critique, de résoudre des problèmes étape par étape et de corriger leurs erreurs de façon autonome.
Exemples :
-
O1 (OpenAI)
-
F1-Preview, R1-Lite-Preview, QwQ-32B-Preview
-
Sky-T1-32B-Preview (le modèle le plus avancé)
LLM vs SLM
- LLM (Large Language Model) — grands modèles de langage contenant des centaines de milliards de paramètres.
Exemples : LLaMA-3.1 (405B paramètres), PaLM (540B paramètres).
- SLM (Small Language Model) — modèles plus petits, plus performants pour des tâches spécifiques.
Exemples : Google's Gemma, Microsoft's Phi-3-mini (3.8B), Phi-3-small (7B).
Taille du modèle (7B, 13B, etc.)
Un modèle d'IA se mesure par son nombre de paramètres (connexions neuronales). Par exemple :
-
7B signifie 7 milliards de paramètres.
-
13B signifie 13 milliards de paramètres.
Plus de paramètres permettent au modèle de mieux comprendre des schémas complexes, mais nécessitent des ressources de calcul plus importantes.
Modèles Open-Source vs Modèles Commerciaux
-
Modèles Open-Source : par ex. Meta-Llama, Qwen — accessibles publiquement.
-
Modèles Propriétaires : par ex. GPT-4, Claude, Gemini — accessibles via des plateformes et des API.
Plateformes d'IA proposant des modèles
Outre les principaux fournisseurs cloud (AWS, Azure, GCP), il existe des plateformes spécialisées qui facilitent l'accès aux modèles, par ex. :
-
Replicate
-
Fireworks AI
-
Together AI
Pour ceux qui préfèrent exécuter les modèles localement, Ollama est une excellente option.
Prompting : comment interagir avec les modèles LLM ?
Le prompt est une instruction ou une requête que l'utilisateur saisit dans le modèle d'IA pour obtenir une réponse.
Types de prompts :
- Prompt système (System Prompt) — définit le rôle et le comportement du modèle.
Exemple : « Vous êtes un assistant serviable. »
- Prompt utilisateur (User Prompt) — requête de l'utilisateur.
Exemple : « Écrivez une histoire. »
Techniques de prompting
Ce sont des manières de formuler les requêtes qui aident à obtenir de meilleures réponses du modèle.
Zero-shot prompting
Le modèle reçoit une question sans exemples. Exemple : « Donnez la définition de l'intelligence artificielle. »
Few-Shot Learning (Apprentissage à partir de quelques exemples)
Dans le contexte des grands modèles de langage (LLM), le concept de few-shot learning désigne la possibilité d'améliorer les performances du modèle en lui fournissant quelques exemples de la tâche à accomplir. Grâce à cela, le modèle comprend mieux les attentes et peut générer des réponses plus pertinentes.
Par exemple, nous pouvons demander au modèle de langage de traduire :
« Traduisez de l'anglais vers le français : How are you today? »
Dans ce cas, aucun exemple de traduction n'est fourni, c'est pourquoi on appelle cela du « zero-shot » (sans exemple).
En revanche, nous pouvons formuler la requête de la manière suivante :
« Traduisez de l'anglais vers le français :
-
Hello → Bonjour
-
Goodbye → Au revoir
Traduisez : How are you today? »
Ici, nous avons fourni deux exemples de traduction correcte, ce qui aide le modèle à mieux exécuter la tâche souhaitée. Cette manière de fournir les données s'appelle « few-shot learning » (apprentissage à partir de quelques exemples).
Chain of Thought (CoT) prompting
Technique dans laquelle le modèle est guidé à travers un problème étape par étape.
Prompt normal : ➡️ « Combien font 15 × 4 ? » Réponse : « 60 »
CoT Prompting : ➡️ « Résolvez étape par étape : Combien font 15 × 4 ? » Réponse :
-
« 15, c'est 10 + 5. »
-
« 10 × 4 = 40. »
-
« 5 × 4 = 20. »
-
« 40 + 20 = 60. » Résultat : « 60 »
Les modèles de raisonnement, tels que o1, montraient auparavant leur processus de réflexion, mais désormais ils donnent simplement la réponse en masquant ce processus.
Token
Les modèles d'IA traitent le texte sous forme de tokens — les plus petites unités textuelles. Exemple : « Model AI » peut être divisé en deux tokens : « Model » et « AI ».
100 tokens ≈ 75 mots.
Quelques bibliothèques de tokenisation :
-
tiktoken (OpenAI)
-
SentencePiece (Google)
Comment fonctionne la tokenisation ?
Phrase : « Expliquez-moi ce qu'est un prompt et un contexte. » ➡️ Peut être divisée en tokens suivants : [« Expliquez », « -moi », « ce », « qu' », « est », « un », « prompt », « et », « un », « contexte », « . »]
Fenêtre de contexte (Context Window)
La fenêtre de contexte est le nombre maximum de tokens que le modèle peut traiter en une seule interaction.
Exemples :
-
GPT-4 : 128K tokens (~96K mots)
-
Claude 3 : 200K tokens (~150K mots)
-
GPT-3.5 : 16K tokens (~12K mots)
Les modèles avec une grande fenêtre de contexte sont adaptés à l'analyse de code et de longs documents. Les modèles avec une petite fenêtre sont meilleurs pour les interactions courtes, comme les chatbots.
Inférence (Inference)
C'est le processus dans lequel le modèle d'IA traite les données d'entrée et génère des réponses.
Paramètres d'inférence :
- Temperature — niveau de créativité du modèle.
Valeur basse → réponses plus prévisibles et cohérentes.
-
Valeur élevée → réponses plus créatives et imprévisibles.
-
Top-K / Top-P — méthode de sélection des mots suivants dans la génération de texte.
-
Max Tokens — nombre maximum de tokens dans la réponse.
-
Latency — temps de réponse du modèle.
Hallucinations en IA
Lorsqu'un grand modèle de langage (LLM) génère un texte incohérent ou non conforme à la source fournie, on parle d'hallucination de LLM (en anglais : LLM hallucination). On appelle également cela fabrication de LLM ou d'autres termes similaires.
Exemple :
Considérons la question suivante posée à ChatGPT :
« Will Smith a-t-il déjà frappé quelqu'un ? »
ChatGPT peut répondre (état de juillet 2023) :
« Il n'existe aucun registre public ni preuve crédible suggérant que Will Smith ait jamais agressé physiquement ou frappé quelqu'un. Il est important d'être prudent lorsqu'on discute ou diffuse des informations non vérifiées sur des personnes, en particulier dans le cas d'allégations graves comme la violence physique. Sur la base des informations disponibles et de la connaissance publique, Will Smith n'a été impliqué dans aucun incident de ce type. »
Bien entendu, cette réponse est erronée, car nous connaissons le célèbre incident lors duquel Will Smith a frappé Chris Rock pendant la cérémonie des Oscars en 2022.
Pourquoi les hallucinations de LLM se produisent-elles ?
Les hallucinations de LLM apparaissent pour deux raisons principales :
-
Le modèle ne « connaît » pas la bonne réponse — si la réponse à une question donnée ne figure pas dans son ensemble d'entraînement, le modèle peut soit refuser de répondre, soit (ce qui est plus probable) générer une information erronée.
-
Le modèle « connaît » la réponse, mais y mêle des contenus fictifs ou subjectifs — la réponse peut contenir des informations fausses ou des éléments basés sur des opinions et des convictions qui ne sont pas factuellement vérifiées.
Chunking (découpage en fragments)
Le chunking est un processus utilisé pour accroître l'efficacité et la précision de la recherche d'informations dans les tâches liées au traitement du langage naturel (NLP). Dans les modèles RAG (Retrieval-Augmented Generation), le texte d'entrée est divisé en unités plus petites et plus faciles à gérer, appelées « chunks » (fragments). Il peut s'agir de phrases, de paragraphes ou d'autres divisions spécifiques à l'application qui découpent un texte plus long en unités plus petites.
L'objectif du chunking est d'améliorer le processus de recherche en permettant au modèle de se concentrer sur des segments de texte plus pertinents et plus précis, plutôt que de traiter des documents entiers d'un coup. Cette approche apporte trois avantages clés :
-
Efficacité — Le travail avec des fragments plus petits accélère le processus de recherche et réduit les besoins en puissance de calcul.
-
Précision — Les fragments plus petits fournissent des informations plus précises, réduisant le bruit et augmentant la pertinence des données obtenues.
-
Scalabilité — Le chunking permet au système de traiter plus efficacement des documents volumineux, facilitant ainsi la mise à l'échelle du modèle RAG pour traiter d'immenses ensembles d'informations.
Dans le modèle RAG, après la division du texte en fragments, chacun d'entre eux est indexé et stocké dans un système de recherche (à la fois sous forme de texte et de vecteur d'embedding). Lorsque l'utilisateur soumet une requête, les fragments les plus pertinents sont recherchés, puis utilisés pour générer une réponse cohérente et informative.
Embeddings (Plongements vectoriels)
Dans le contexte des grands modèles de langage (Large Language Models, LLM), les plongements vectoriels (vector embeddings) sont une forme de représentation qui capture de manière compacte le sens sémantique ou le contexte des mots et des phrases. Ce sont des vecteurs de nombres réels (float), où chaque dimension peut refléter une caractéristique différente décrivant le sens d'un concept donné.
Les plongements vectoriels sont également appelés « représentations denses » (dense representations), car ils utilisent des espaces vectoriels continus pour représenter les requêtes et les documents. Cela contraste avec la « représentation creuse » (sparse representation) plus traditionnelle, dans laquelle chaque mot ou expression fait partie d'un vecteur, et la correspondance se fait en comparant ces mots ou expressions entre la requête et le document.
-
Les plongements de mots (word embeddings) sont des vecteurs d'embedding attribuant à chaque mot sa représentation vectorielle.
-
Les plongements de phrases (sentence embeddings) projettent des phrases entières, des paragraphes ou n'importe quels fragments de texte en vecteurs d'embedding.
Exemple de plongement de phrase :
Un fragment de texte (marqué en rouge à gauche) est représenté par un vecteur de nombres réels affiché à droite.
Les plongements vectoriels sont utilisés comme données d'entrée dans diverses tâches NLP, telles que la classification de texte, l'analyse de sentiment ou la traduction automatique. Dans les applications de type retrieval-augmented generation (RAG), les modèles de plongements de phrases jouent un rôle clé, permettant de faire correspondre les faits pertinents des données aux requêtes de l'utilisateur.
Pré-entraînement (Pre-Training)
Processus au cours duquel le modèle est entraîné sur d'immenses ensembles de données (livres, sites web, articles) afin d'apprendre le langage.
Reinforcement Learning with Human Feedback (RLHF)
Technique consistant à récompenser le modèle pour ses bonnes réponses et à corriger les mauvaises.
Direct Preference Optimization (DPO)
Méthode d'optimisation du modèle sans le processus complexe du RLHF — l'IA apprend à la place en se basant sur les préférences des utilisateurs.
RAG (Retrieval-Augmented Generation)
Technique permettant au modèle d'accéder à des bases de données externes au lieu de se fier uniquement à ses connaissances d'entraînement.
Comment fonctionne le RAG ?
-
Recherche (Retrieval) — le modèle trouve les documents pertinents dans la base de données.
-
Génération (Generation) — le modèle utilise ces documents pour générer une réponse plus précise.
Concepts clés du RAG
-
Embeddings — conversion des données (par ex. des documents) en nombres pour que l'IA puisse les comprendre.
-
Base vectorielle (Vector Database) — base de données spécialisée pour stocker les embeddings.
-
Semantic Search — recherche basée sur le sens, et non uniquement sur les mots-clés.
Résumé
Dans ce guide, nous avons abordé les termes clés liés à l'IA, tels que : les modèles d'IA (LLM, SLM, multimodalité, modèles de raisonnement), le prompting et les techniques d'interaction avec les modèles, la tokenisation et les fenêtres de contexte, l'inférence, les hallucinations et les paramètres de génération, l'entraînement, le fine-tuning, le RLHF, le RAG.
Et ensuite ? Cet article sera enrichi et des liens vers d'autres sources ou vidéos dans lesquelles le sujet sera encore mieux expliqué y seront ajoutés. Dans les prochains articles, nous approfondirons le thème des Agents IA et des aspects plus avancés du RAG.
Merci de votre attention ! Bonne exploration du monde de l'IA !