-
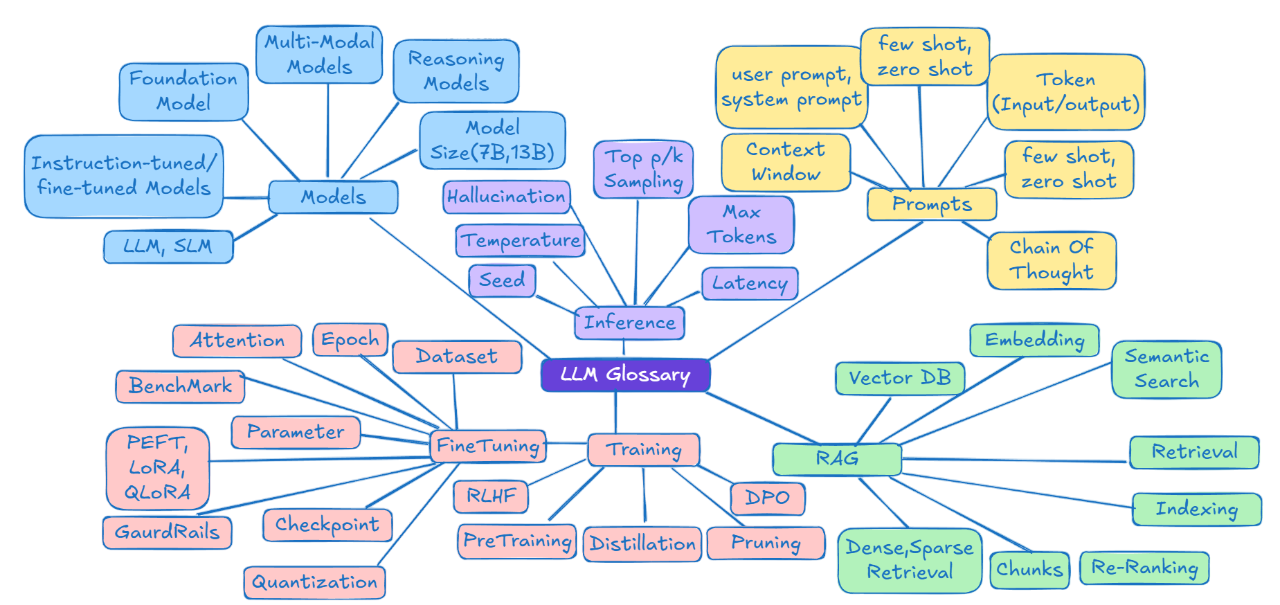
Der Artikel liefert ein Glossar der Begriffe rund um Large Language Models (LLM) und KI und erklärt verschiedene Aspekte wie Modelltypen, Foundation Models oder Inferenz.
-
Er enthält Verweise auf konkrete Modelle wie ChatGPT oder Claude und erläutert Konzepte wie das Kontextfenster oder Halluzinationen.
-
Die Übersetzung ins Deutsche wurde auf Basis einer Zusammenfassung erstellt, aufgrund technischer Schwierigkeiten bei der vollständigen Übersetzung des Originaltextes.

KI-Modelle: Grundlegende Begriffe
Foundation Models (Basismodelle)
Dies sind große KI-Modelle, die auf riesigen Datensätzen vortrainiert wurden und daher umfassende Fähigkeiten zum Verstehen und Generieren von Text, Bildern, Code, Audio und Video besitzen. Sie dienen als Ausgangspunkt für die Erstellung spezialisierter Modelle durch weiteres Training oder Fine-Tuning.
Beispiele:
-
GPT (Generative Pre-trained Transformers) – das Basismodell aller GPT-Versionen, einschließlich GPT-4o.
-
DALL·E – ein Modell zur Bildgenerierung.
-
Stable Diffusion – ein Modell zur Bildgenerierung.
-
AudioGen – ein Modell zur Text-zu-Audio-Konvertierung.
-
Whisper – ein Modell zur Audio-zu-Text-Konvertierung.
Fine-tuned Models (Feinabgestimmte Modelle)
Dies sind Modelle, die für die Ausführung bestimmter Aufgaben auf Daten aus einem bestimmten Fachgebiet trainiert wurden. Beispielsweise wird ein allgemeines Sprachmodell, das auf juristischen Dokumenten feinabgestimmt wurde, auf das Verfassen juristischer Texte spezialisiert.
Beispiele:
-
CodeLlama – eine feinabgestimmte Version von LLaMA für die Programmierung.
-
CodeQwen – eine feinabgestimmte Version von Qwen für die Programmierung.
Instruction-tuned Models (Instruktionsabgestimmte Modelle)
Dies sind Modelle, die darauf trainiert wurden, in Echtzeit den Anweisungen des Nutzers zu folgen.
Beispiel:
Anweisung: „Übersetze diesen Text ins Spanische" Eingabe: „Good morning" Ausgabe: „Buenos días"
Feinabgestimmte Modelle und instruktionsabgestimmte Modelle werden nicht von Grund auf neu erstellt – sie sind lediglich angepasste Versionen von Foundation Models.
Multimodale Modelle (Multimodal Models)
Dies sind KI-Modelle, die verschiedene Datentypen als Ein- und Ausgabe verarbeiten können.
Beispiele:
-
ChatGPT-4o (OpenAI)
-
Gemini (Google) Beide Modelle akzeptieren verschiedene Eingaben wie Text, Bilder und Dokumente und generieren verschiedene Ausgabeformate.
Reasoning Models (Reasoning-Modelle)
Dies ist die neueste Generation von KI-Modellen, die kritisch denken, Probleme Schritt für Schritt lösen und Fehler selbständig korrigieren können.
Beispiele:
-
O1 (OpenAI)
-
F1-Preview, R1-Lite-Preview, QwQ-32B-Preview
-
Sky-T1-32B-Preview (das fortschrittlichste Modell)
LLM vs SLM
- LLM (Large Language Model) – große Sprachmodelle mit Hunderten von Milliarden Parametern.
Beispiele: LLaMA-3.1 (405B Parameter), PaLM (540B Parameter).
- SLM (Small Language Model) – kleinere Modelle, effizienter für spezifische Aufgaben.
Beispiele: Google's Gemma, Microsoft's Phi-3-mini (3.8B), Phi-3-small (7B).
Modellgröße (7B, 13B, etc.)
Ein KI-Modell wird an der Anzahl seiner Parameter (neuronale Verbindungen) gemessen. Zum Beispiel:
-
7B bedeutet 7 Milliarden Parameter.
-
13B bedeutet 13 Milliarden Parameter.
Mehr Parameter ermöglichen es dem Modell, komplexe Muster besser zu verstehen, erfordern jedoch größere Rechenressourcen.
Open-Source-Modelle vs. kommerzielle Modelle
-
Open-Source-Modelle: z.B. Meta-Llama, Qwen – öffentlich zugänglich.
-
Proprietäre Modelle: z.B. GPT-4, Claude, Gemini – über Plattformen und APIs verfügbar.
KI-Plattformen, die Modelle anbieten
Neben den großen Cloud-Anbietern (AWS, Azure, GCP) gibt es spezialisierte Plattformen, die den Zugang zu Modellen erleichtern, z.B.:
-
Replicate
-
Fireworks AI
-
Together AI
Für Personen, die Modelle lokal ausführen möchten, ist Ollama eine hervorragende Option.
Prompting: Wie kommuniziert man mit LLM-Modellen?
Ein Prompt ist eine Anweisung oder Anfrage, die der Nutzer in ein KI-Modell eingibt, um eine Antwort zu erhalten.
Arten von Prompts:
- System-Prompt (System Prompt) – definiert die Rolle und das Verhalten des Modells.
Beispiel: „Du bist ein hilfreicher Assistent."
- Nutzer-Prompt (User Prompt) – Anfrage des Nutzers.
Beispiel: „Schreibe eine Geschichte."
Prompting-Techniken
Dies sind Methoden der Frageformulierung, die helfen, bessere Antworten vom Modell zu erhalten.
Zero-Shot Prompting
Das Modell erhält eine Frage ohne Beispiele. Beispiel: „Gib eine Definition von Künstlicher Intelligenz."
Few-Shot Learning (Lernen mit wenigen Beispielen)
Im Kontext großer Sprachmodelle (LLMs) bezieht sich der Begriff Few-Shot Learning auf die Möglichkeit, die Leistung eines Modells zu verbessern, indem man ihm einige Beispiele der auszuführenden Aufgabe gibt. Dadurch versteht das Modell die Erwartungen besser und kann treffendere Antworten generieren.
Zum Beispiel können wir ein Sprachmodell um eine Übersetzung bitten:
„Übersetze von Englisch nach Französisch: How are you today?"
In diesem Fall wurden keine Übersetzungsbeispiele gegeben, daher nennt man dies „Zero-Shot" (ohne Beispiele).
Alternativ können wir die Anfrage wie folgt formulieren:
„Übersetze von Englisch nach Französisch:
-
Hello → Bonjour
-
Goodbye → Au revoir
Übersetze: How are you today?"
Hier haben wir zwei Beispiele korrekter Übersetzungen bereitgestellt, was dem Modell hilft, die gewünschte Aufgabe besser auszuführen. Diese Art der Dateneingabe nennt man „Few-Shot Learning" (Lernen mit wenigen Beispielen).
Chain of Thought (CoT) Prompting
Eine Technik, bei der das Modell Schritt für Schritt durch ein Problem geführt wird.
Normaler Prompt: ➡️ „Was ist 15 × 4?" Antwort: „60"
CoT Prompting: ➡️ „Löse Schritt für Schritt: Was ist 15 × 4?" Antwort:
-
„15 ist 10 + 5."
-
„10 × 4 = 40."
-
„5 × 4 = 20."
-
„40 + 20 = 60." Ergebnis: „60"
Reasoning-Modelle wie o1 zeigten früher ihren Denkprozess, geben nun aber einfach die Antwort aus und verbergen diesen Prozess.
Token
KI-Modelle verarbeiten Text in Form von Tokens – den kleinsten Texteinheiten. Beispielsweise: „KI-Modell" kann in zwei Tokens aufgeteilt werden: „KI" und „Modell".
100 Tokens ≈ 75 Wörter.
Einige Bibliotheken zur Tokenisierung:
-
tiktoken (OpenAI)
-
SentencePiece (Google)
Wie funktioniert Tokenisierung?
Satz: „Erkläre mir, was ein Prompt und Kontext ist." ➡️ Kann in folgende Tokens aufgeteilt werden: [„Erkläre", „mir", „, ", „was", „ein", „Prompt", „und", „Kontext", „ist", „."]
Kontextfenster (Context Window)
Das Kontextfenster ist die maximale Anzahl an Tokens, die ein Modell in einer einzelnen Interaktion verarbeiten kann.
Beispiele:
-
GPT-4: 128K Tokens (~96K Wörter)
-
Claude 3: 200K Tokens (~150K Wörter)
-
GPT-3.5: 16K Tokens (~12K Wörter)
Modelle mit großem Kontextfenster eignen sich für Code-Analyse und lange Dokumente. Modelle mit kleinem Fenster sind besser für kurze Interaktionen, z.B. Chatbots.
Inferenz (Inference)
Dies ist der Prozess, bei dem ein KI-Modell Eingabedaten verarbeitet und Antworten generiert.
Inferenz-Parameter:
- Temperature – der Kreativitätsgrad des Modells.
Niedriger Wert → vorhersagbarere und konsistentere Antworten.
-
Hoher Wert → kreativere und unvorhersehbarere Antworten.
-
Top-K / Top-P – die Methode zur Auswahl der nächsten Wörter bei der Textgenerierung.
-
Max Tokens – die maximale Anzahl an Tokens in der Antwort.
-
Latency – die Antwortzeit des Modells.
Halluzinationen in KI
Wenn ein großes Sprachmodell (LLM) Text generiert, der sinnlos ist oder nicht mit der bereitgestellten Quelle übereinstimmt, bezeichnet man dies als LLM-Halluzination (engl. LLM hallucination). Dies wird auch als LLM-Fabrikation oder mit ähnlichen Begriffen bezeichnet.
Beispiel:
Betrachten wir folgende Frage an ChatGPT:
„Hat Will Smith jemals jemanden geschlagen?"
ChatGPT könnte antworten (Stand Juli 2023):
„Es gibt keine öffentlichen Aufzeichnungen oder glaubwürdigen Beweise dafür, dass Will Smith jemals jemanden physisch angegriffen oder geschlagen hat. Es ist wichtig, bei der Diskussion oder Verbreitung unbestätigter Informationen über Personen vorsichtig zu sein, insbesondere bei schwerwiegenden Vorwürfen wie physischer Gewalt. Basierend auf verfügbaren Informationen und öffentlichem Wissen war Will Smith an keinem solchen Vorfall beteiligt."
Natürlich ist diese Antwort falsch, da wir den berühmten Vorfall kennen, bei dem Will Smith Chris Rock während der Oscar-Verleihung 2022 schlug.
Warum treten LLM-Halluzinationen auf?
LLM-Halluzinationen treten aus zwei Hauptgründen auf:
-
Das Modell „kennt" die richtige Antwort nicht – wenn die Antwort auf eine bestimmte Frage nicht in seinem Trainingsdatensatz enthalten ist, kann das Modell entweder die Antwort verweigern oder (wahrscheinlicher) falsche Informationen generieren.
-
Das Modell „kennt" die Antwort, webt aber fiktive oder subjektive Inhalte ein – die Antwort kann unwahre Informationen oder Elemente enthalten, die auf Meinungen und Überzeugungen basieren, die faktisch nicht verifiziert sind.
Chunking (Aufteilung in Fragmente)
Chunking ist ein Prozess, der zur Steigerung der Effektivität und Genauigkeit der Informationssuche bei Aufgaben der natürlichen Sprachverarbeitung (NLP) eingesetzt wird. In RAG-Modellen (Retrieval-Augmented Generation) wird der Eingabetext in kleinere, leichter handhabbare Einheiten unterteilt, sogenannte „Chunks" (Fragmente). Dies können Sätze, Absätze oder andere, anwendungsspezifische Aufteilungen eines größeren Textes in kleinere Einheiten sein.
Das Ziel des Chunking ist die Verbesserung des Suchprozesses, indem das Modell sich auf relevantere und präzisere Textsegmente konzentrieren kann, anstatt ganze Dokumente auf einmal zu verarbeiten. Dieser Ansatz bringt drei wesentliche Vorteile:
-
Effizienz – Die Arbeit mit kleineren Fragmenten beschleunigt den Suchprozess und reduziert den Bedarf an Rechenleistung.
-
Genauigkeit – Kleinere Fragmente liefern präzisere Informationen, reduzieren Rauschen und erhöhen die Treffergenauigkeit der gewonnenen Daten.
-
Skalierbarkeit – Chunking ermöglicht es dem System, größere Dokumente effizienter zu verarbeiten, was die Skalierung des RAG-Modells zur Verarbeitung riesiger Informationsmengen erleichtert.
Im RAG-Modell wird nach der Aufteilung des Textes in Fragmente jedes einzelne indexiert und im Suchsystem gespeichert (sowohl als Text als auch als Vektor-Embedding). Wenn ein Nutzer eine Anfrage eingibt, werden die relevantesten Fragmente gesucht, die anschließend zur Generierung einer kohärenten und informativen Antwort verwendet werden.
Embeddings (Einbettungen)
Im Kontext großer Sprachmodelle (Large Language Models, LLM) sind Vektor-Embeddings eine Form der Darstellung, die in kompakter Form die semantische Bedeutung oder den Kontext von Wörtern und Sätzen erfasst. Es handelt sich um Vektoren reeller Zahlen (Float), wobei jede Dimension ein anderes Merkmal widerspiegeln kann, das die Bedeutung eines Konzepts beschreibt.
Vektor-Embeddings werden auch als „dichte Repräsentationen" (Dense Representations) bezeichnet, da sie kontinuierliche Vektorräume zur Darstellung von Anfragen und Dokumenten nutzen. Dies steht im Gegensatz zur traditionelleren „dünnbesetzten Repräsentation" (Sparse Representation), bei der jedes Wort oder jede Phrase Teil eines Vektors ist und der Abgleich durch Vergleich dieser Wörter oder Phrasen zwischen Anfrage und Dokument erfolgt.
-
Wort-Embeddings (Word Embeddings) sind Einbettungsvektoren, die jedem Wort seine Vektorrepräsentation zuweisen.
-
Satz-Embeddings (Sentence Embeddings) bilden ganze Sätze, Absätze oder beliebige Textfragmente auf Einbettungsvektoren ab.
Beispiel eines Satz-Embeddings:
Ein Textfragment (links rot markiert) wird durch einen Vektor reeller Zahlen dargestellt, der auf der rechten Seite gezeigt wird.
Vektor-Embeddings werden als Eingabedaten in verschiedenen NLP-Aufgaben verwendet, wie Textklassifikation, Sentiment-Analyse oder maschinelle Übersetzung. In Retrieval-Augmented Generation (RAG)-Anwendungen spielen Satz-Embedding-Modelle eine Schlüsselrolle, indem sie relevante Fakten aus den Daten mit den Anfragen des Nutzers abgleichen.
Pre-Training (Vortraining)
Ein Prozess, bei dem ein Modell auf riesigen Datensätzen (Bücher, Websites, Artikel) trainiert wird, um Sprache zu erlernen.
Reinforcement Learning with Human Feedback (RLHF)
Eine Technik, bei der das Modell für gute Antworten belohnt und bei fehlerhaften korrigiert wird.
Direct Preference Optimization (DPO)
Eine Methode zur Modelloptimierung ohne den komplizierten RLHF-Prozess – stattdessen lernt die KI auf Basis von Nutzerpräferenzen.
RAG (Retrieval-Augmented Generation)
Eine Technik, die dem Modell Zugang zu externen Datenbanken ermöglicht, anstatt sich ausschließlich auf das Trainingswissen zu verlassen.
Wie funktioniert RAG?
-
Retrieval (Abruf) – das Modell findet relevante Dokumente in der Datenbank.
-
Generation (Generierung) – das Modell nutzt diese Dokumente, um eine genauere Antwort zu generieren.
Schlüsselbegriffe von RAG
-
Embeddings – Konvertierung von Daten (z.B. Dokumenten) in Zahlen, damit die KI sie verstehen kann.
-
Vektordatenbank (Vector Database) – eine spezielle Datenbank zur Speicherung von Embeddings.
-
Semantic Search – Suche basierend auf Bedeutung, nicht nur auf Schlüsselwörtern.
Zusammenfassung
In diesem Leitfaden haben wir die wichtigsten Begriffe rund um KI behandelt, wie: KI-Modelle (LLM, SLM, Multimodalität, Reasoning Models), Prompting und Techniken der Modellinteraktion, Tokenisierung und Kontextfenster, Inferenz, Halluzinationen und Generierungsparameter, Training, Fine-Tuning, RLHF, RAG.
Wie geht es weiter? Dieser Artikel wird erweitert und es werden Links zu anderen Quellen oder Videos hinzugefügt, in denen das Thema noch besser erklärt wird. In zukünftigen Artikeln werden wir das Thema KI-Agenten und fortgeschrittenere Aspekte von RAG vertiefen.
Vielen Dank für Ihre Aufmerksamkeit! Viel Freude beim Entdecken der Welt der KI!