-
Artykuł dostarcza słownik terminów związanych z dużymi modelami językowymi (LLM) i AI, tłumacząc różne aspekty, takie jak typy modeli, podstawowe modele, czy wnioskowanie.
-
Zawiera odniesienia do konkretnych modeli, jak ChatGPT czy Claude, oraz wyjaśnia koncepcje, takie jak okno kontekstowe czy halucynacja.
-
Tłumaczenie na polski zostało wykonane na podstawie streszczenia, z uwagi na trudności techniczne w pełnym przetłumaczeniu oryginalnego tekstu.

Modele AI: Podstawowe Pojęcia
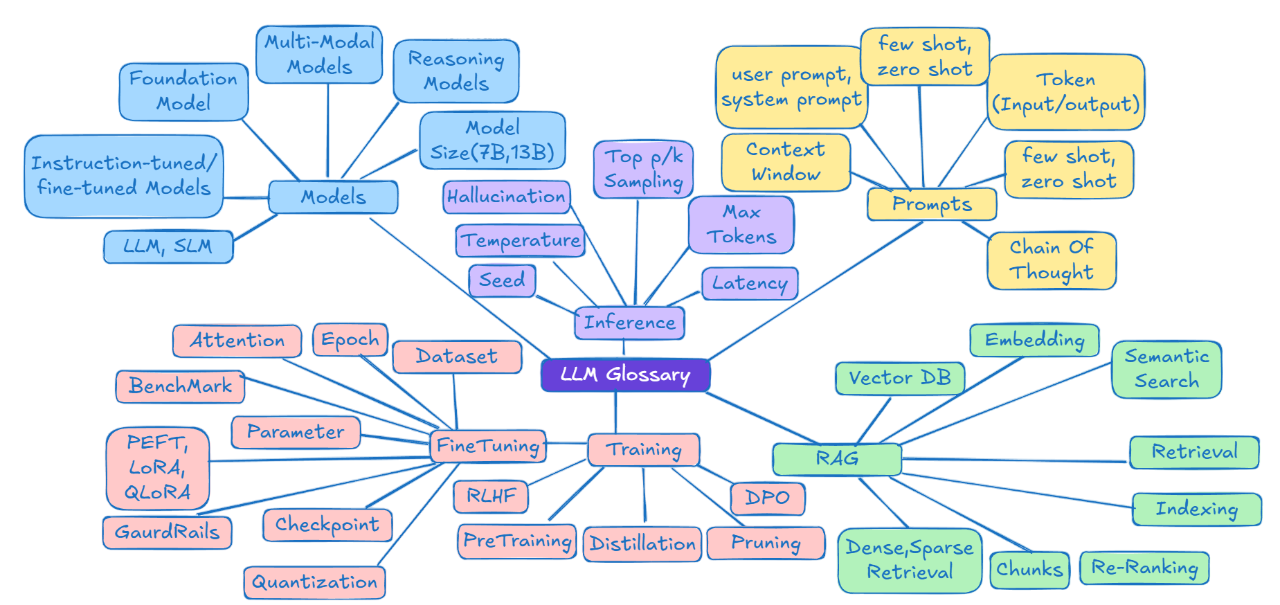
Modele bazowe (Foundation Models)
To duże modele AI wstępnie wytrenowane na ogromnych zbiorach danych, dzięki czemu mają szerokie możliwości rozumienia i generowania tekstu, obrazów, kodu, dźwięku i wideo. Służą jako punkt wyjścia do tworzenia bardziej wyspecjalizowanych modeli poprzez dalsze szkolenie lub dostrajanie.
Przykłady:
-
GPT (Generative Pre-trained Transformers) – model bazowy wszystkich wersji GPT, w tym GPT-4o.
-
DALL·E – model do generowania obrazów.
-
Stable Diffusion – model do generowania obrazów.
-
AudioGen – model do konwersji tekstu na dźwięk.
-
Whisper – model do konwersji dźwięku na tekst.
Dostrajanie Modeli (Fine-tuned Models)
To modele wytrenowane do wykonywania określonych zadań na danych z konkretnej dziedziny. Na przykład ogólny model językowy dostrojony na dokumentach prawnych staje się wyspecjalizowany w pisaniu tekstów prawniczych.
Przykłady:
-
CodeLlama – dostrojona wersja LLaMA do programowania.
-
CodeQwen – dostrojona wersja Qwen do programowania.
Modele dostrojone do wykonywania instrukcji (Instruction-tuned Models)
To modele szkolone tak, aby w czasie rzeczywistym podążały za instrukcjami użytkownika.
Przykład:
Instrukcja: „Przetłumacz ten tekst na hiszpański”Wejście: „Good morning”Wyjście: „Buenos días”
Modele dostrojone oraz modele dostrojone do wykonywania instrukcji nie są budowane od zera – są po prostu dostosowanymi wersjami modeli bazowych.
Modele multimodalne (Multimodal Models)
To modele AI, które mogą przetwarzać różne typy danych na wejściu i wyjściu.
Przykłady:
-
ChatGPT-4o (OpenAI)
-
Gemini (Google)Oba te modele akceptują różne wejścia, takie jak tekst, obrazy i dokumenty, oraz generują różne formaty wyjściowe.
Modele rozumowania (Reasoning Models)
To najnowsza generacja modeli AI, które potrafią myśleć krytycznie, rozwiązywać problemy krok po kroku i samodzielnie korygować błędy.
Przykłady:
-
O1 (OpenAI)
-
F1-Preview, R1-Lite-Preview, QwQ-32B-Preview
-
Sky-T1-32B-Preview (najbardziej zaawansowany model)
LLM vs SLM
- LLM (Large Language Model) – duże modele językowe zawierające setki miliardów parametrów.
Przykłady: LLaMA-3.1 (405B parametrów), PaLM (540B parametrów).
- SLM (Small Language Model) – mniejsze modele, bardziej wydajne dla specyficznych zadań.
Przykłady: Google’s Gemma, Microsoft’s Phi-3-mini (3.8B), Phi-3-small (7B).
Rozmiar modelu (7B, 13B, itd.)
Model AI jest mierzony liczbą parametrów (połączeń neuronowych). Na przykład:
-
7B oznacza 7 miliardów parametrów.
-
13B oznacza 13 miliardów parametrów.
Więcej parametrów pozwala modelowi lepiej rozumieć złożone wzorce, ale wymaga większych zasobów obliczeniowych.
Modele Open-Source vs Modele Komercyjne
-
Modele Open-Source: np. Meta-Llama, Qwen – dostępne publicznie.
-
Modele Własnościowe: np. GPT-4, Claude, Gemini – dostępne przez platformy i API.
Platformy AI oferujące modele
Poza głównymi dostawcami chmury (AWS, Azure, GCP), istnieją specjalistyczne platformy, które ułatwiają dostęp do modeli, np.:
-
Replicate
-
Fireworks AI
-
Together AI
Dla osób preferujących uruchamianie modeli lokalnie, Ollama to świetna opcja.
Prompting: Jak rozmawiać z modelami LLM?
Prompt to instrukcja lub zapytanie, które użytkownik wpisuje do modelu AI, aby uzyskać odpowiedź.
Rodzaje promptów:
- Prompt systemowy (System Prompt) – definiuje rolę i zachowanie modelu.
Przykład: „Jesteś pomocnym asystentem.”
- Prompt użytkownika (User Prompt) – zapytanie od użytkownika.
Przykład: „Napisz historię.”
Techniki promptingu
To sposoby formułowania zapytań, które pomagają uzyskać lepsze odpowiedzi od modelu.
Zero-shot prompting
Model otrzymuje pytanie bez przykładów.Przykład: „Podaj definicję sztucznej inteligencji.”
Few-Shot Learning (Uczenie na kilku przykładach)
W kontekście dużych modeli językowych (LLMs) pojęcie few-shot learning odnosi się do możliwości poprawy wydajności modelu poprzez dostarczenie mu kilku przykładów zadania, które ma wykonać. Dzięki temu model lepiej rozumie oczekiwania i może generować trafniejsze odpowiedzi.
Na przykład, możemy poprosić model językowy o tłumaczenie:
„Przetłumacz z angielskiego na francuski: How are you today?”
W tym przypadku nie podano żadnych przykładów tłumaczenia, więc taki przypadek nazywa się „zero-shot” (bez przykładów).
Z kolei, możemy sformułować zapytanie w następujący sposób:
„Przetłumacz z angielskiego na francuski:
-
Hello → Bonjour
-
Goodbye → Au revoir
Przetłumacz: How are you today?”
Tutaj dostarczyliśmy dwa przykłady poprawnego tłumaczenia, co pomaga modelowi lepiej wykonać zadanie, na którym nam zależy. Taki sposób podawania danych nazywa się „few-shot learning” (uczenie na kilku przykładach).
Chain of Thought (CoT) prompting
Technika, w której model jest prowadzony przez problem krok po kroku.
Normalny prompt:➡️ „Ile to 15 × 4?”Odpowiedź: „60”
CoT Prompting:➡️ „Rozwiąż krok po kroku: Ile to 15 × 4?”Odpowiedź:
-
„15 to 10 + 5.”
-
„10 × 4 = 40.”
-
„5 × 4 = 20.”
-
„40 + 20 = 60.”📌 Wynik: „60”
Modele rozumowania, takie jak o1, wcześniej pokazywały swój proces myślenia, ale teraz po prostu podają odpowiedź, ukrywając ten proces.
Token
Modele AI przetwarzają tekst w postaci tokenów – najmniejszych jednostek tekstowych.🔹 Przykładowo: „Model AI” może zostać podzielony na dwa tokeny: „Model” i „AI”.
100 tokenów ≈ 75 słów.
Niektóre biblioteki do tokenizacji:
-
tiktoken (OpenAI)
-
SentencePiece (Google)
Jak działa tokenizacja?
Zdanie: „Wyjaśnij mi, czym jest prompt i kontekst.”➡️ Może zostać podzielone na następujące tokeny: [„Wyjaśnij”, „mi”, „, ”, „czym”, „jest”, „prompt”, „i”, „kontekst”, „.”]
Okno kontekstowe (Context Window)
Okno kontekstowe to maksymalna liczba tokenów, jakie model może przetworzyć w jednej interakcji.
Przykłady:
-
GPT-4: 128K tokenów (~96K słów)
-
Claude 3: 200K tokenów (~150K słów)
-
GPT-3.5: 16K tokenów (~12K słów)
🔹 Modele z dużym oknem kontekstowym sprawdzają się w analizie kodu i długich dokumentów.🔹 Modele z małym oknem są lepsze do krótkich interakcji, np. chatbotów.
Inferencja (Inference)
To proces, w którym model AI przetwarza dane wejściowe i generuje odpowiedzi.
Parametry inferencji:
- Temperature – poziom kreatywności modelu.
Niska wartość → bardziej przewidywalne i spójne odpowiedzi.
-
Wysoka wartość → bardziej kreatywne i nieprzewidywalne odpowiedzi.
-
Top-K / Top-P – sposób wyboru kolejnych słów w generacji tekstu.
-
Max Tokens – maksymalna liczba tokenów w odpowiedzi.
-
Latency – czas odpowiedzi modelu.
Halucynacje w AI
Kiedy duży model językowy (LLM) generuje tekst, który jest bezsensowny lub niezgodny z dostarczonym źródłem, określa się to jako halucynację LLM (ang. LLM hallucination). Jest to także nazywane fabrykacją LLM lub innymi podobnymi terminami.
Przykład:
Rozważmy następujące pytanie zadane ChatGPT:
„Czy Will Smith kiedykolwiek uderzył kogoś?”
ChatGPT może odpowiedzieć (stan na lipiec 2023):
„Nie ma żadnych publicznych zapisów ani wiarygodnych dowodów sugerujących, że Will Smith kiedykolwiek kogoś fizycznie zaatakował lub uderzył. Ważne jest, aby być ostrożnym przy omawianiu lub rozpowszechnianiu niezweryfikowanych informacji o osobach, szczególnie w przypadku poważnych zarzutów, takich jak przemoc fizyczna. Na podstawie dostępnych informacji i wiedzy publicznej, Will Smith nie brał udziału w żadnych tego typu incydentach.”
Oczywiście ta odpowiedź jest błędna, ponieważ wiemy o słynnym incydencie, w którym Will Smith uderzył Chrisa Rocka podczas ceremonii Oscarów w 2022 roku.
Dlaczego występują halucynacje LLM?
Halucynacje LLM pojawiają się z dwóch głównych powodów:
-
Model nie „zna” poprawnej odpowiedzi – jeśli odpowiedź na dane pytanie nie jest zawarta w jego zbiorze treningowym, model może albo odmówić odpowiedzi, albo (co bardziej prawdopodobne) wygenerować błędną informację.
-
Model „zna” odpowiedź, ale wplata fikcyjne lub subiektywne treści – odpowiedź może zawierać nieprawdziwe informacje lub elementy oparte na opiniach i przekonaniach, które nie są faktycznie zweryfikowane.
Chunking (dzielenie na fragmenty)
Chunking to proces wykorzystywany do zwiększenia efektywności i dokładności wyszukiwania informacji w zadaniach związanych z przetwarzaniem języka naturalnego (NLP). W modelach RAG (Retrieval-Augmented Generation) tekst wejściowy jest dzielony na mniejsze, łatwiejsze do zarządzania jednostki, zwane „chunkami” (fragmentami). Mogą to być zdania, akapity lub inne, specyficzne dla danej aplikacji podziały większego tekstu na mniejsze jednostki.
Celem chunkingu jest poprawa procesu wyszukiwania poprzez umożliwienie modelowi skupienia się na bardziej istotnych i precyzyjnych segmentach tekstu, zamiast przetwarzać całe dokumenty naraz. Podejście to przynosi trzy kluczowe korzyści:
-
Efektywność – Praca z mniejszymi fragmentami przyspiesza proces wyszukiwania i zmniejsza zapotrzebowanie na moc obliczeniową.
-
Dokładność – Mniejsze fragmenty dostarczają bardziej precyzyjnych informacji, redukując szum i zwiększając trafność uzyskiwanych danych.
-
Skalowalność – Chunking umożliwia systemowi bardziej efektywne przetwarzanie większych dokumentów, co ułatwia skalowanie modelu RAG do obsługi ogromnych zbiorów informacji.
W modelu RAG, po podzieleniu tekstu na fragmenty, każdy z nich jest indeksowany i przechowywany w systemie wyszukiwania (zarówno jako tekst, jak i jako wektor osadzenia – embedding). Gdy użytkownik wprowadza zapytanie, wyszukiwane są najbardziej odpowiednie fragmenty, które następnie są wykorzystywane do wygenerowania spójnej i informacyjnej odpowiedzi.
Osadzenia (Embeddings)
W kontekście dużych modeli językowych (Large Language Models, LLM), osadzenia wektorowe (vector embeddings) to forma reprezentacji, która w zwartej postaci uchwytuje semantyczne znaczenie lub kontekst słów i zdań. Są to wektory liczb rzeczywistych (float), gdzie każda wymiar może odzwierciedlać inną cechę, opisującą znaczenie danego konceptu.
Osadzenia wektorowe są również nazywane „gęstymi reprezentacjami” (dense representations), ponieważ wykorzystują ciągłe przestrzenie wektorowe do reprezentowania zapytań i dokumentów. Jest to kontrast w stosunku do bardziej tradycyjnej „rzadkiej reprezentacji” (sparse representation), w której każde słowo lub fraza jest częścią wektora, a dopasowanie odbywa się poprzez porównywanie tych słów lub fraz między zapytaniem a dokumentem.
-
Osadzenia słów (word embeddings) to wektory osadzeń przypisujące każdemu słowu jego reprezentację wektorową.
-
Osadzenia zdań (sentence embeddings) mapują całe zdania, akapity lub dowolne fragmenty tekstu na wektory osadzeń.
Przykład osadzenia zdania:
Fragment tekstu (zaznaczony na czerwono po lewej stronie) jest reprezentowany przez wektor liczb rzeczywistych pokazany po prawej stronie.
Osadzenia wektorowe są wykorzystywane jako dane wejściowe w różnych zadaniach NLP, takich jak klasyfikacja tekstu, analiza sentymentu czy tłumaczenie maszynowe. W aplikacjach typu retrieval-augmented generation (RAG) modele osadzeń zdań odgrywają kluczową rolę, umożliwiając dopasowanie istotnych faktów z danych do zapytań użytkownika.
Pre-trening (Pre-Training)
Proces, w którym model jest szkolony na ogromnych zbiorach danych (książki, strony internetowe, artykuły) w celu nauczenia się języka.
Reinforcement Learning with Human Feedback (RLHF)
Technika polegająca na nagradzaniu modelu za dobre odpowiedzi i korygowaniu błędnych.
Direct Preference Optimization (DPO)
Metoda optymalizacji modelu bez skomplikowanego procesu RLHF – zamiast tego AI uczy się na podstawie preferencji użytkowników.
RAG (Retrieval-Augmented Generation)
Technika umożliwiająca modelowi dostęp do zewnętrznych baz danych zamiast polegania wyłącznie na wiedzy treningowej.
Jak działa RAG?
-
Wyszukiwanie (Retrieval) – model znajduje odpowiednie dokumenty w bazie danych.
-
Generowanie (Generation) – model używa tych dokumentów, aby wygenerować dokładniejszą odpowiedź.
Kluczowe pojęcia RAG
-
Embeddings – konwersja danych (np. dokumentów) na liczby, aby AI mogło je zrozumieć.
-
Baza wektorowa (Vector Database) – specjalna baza danych do przechowywania embeddings.
-
Semantic Search – wyszukiwanie na podstawie znaczenia, a nie tylko słów kluczowych.
Podsumowanie
W tym przewodniku omówiliśmy kluczowe terminy związane z AI, takie jak: ✅ Modele AI (LLM, SLM, multimodalność, reasoning models)✅ Prompting i techniki interakcji z modelami✅ Tokenizacja i okna kontekstowe✅ Inferencja, halucynacje i parametry generacji✅ Trening, fine-tuning, RLHF, RAG 📌 Co dalej?Ten artykuł będzie rozszerzany i będą z niego odsyłacze do innych źródeł lub filmów w którym temat ten będzie jeszcze lepiej wyjaśniony. W przyszłych artykułach zgłębimy temat Agentów AI i bardziej zaawansowanych aspektów RAG. 🎉 Dziękujemy za uwagę! Miłego odkrywania świata AI! 🚀